
A PIRÂMIDE DA WEB SEMÂNTICA PARA BIBLIOTECÁRIOS NÃO EGÍPCIOS
A história sobre o World Wide Web é bem conhecida. Nasce em 1989, nos laboratórios do Conseil Européen pour la Recherche Nucléaire (CERN), e desde então se converte em espaço global de informação. Universo formado de milhares de milhões de páginas eletrônicas de conteúdos os mais diversificados. Esta quantidade e diversidade garante a Web possuir informação sobre quase qualquer tema. O que deveria sugerir uma vantagem deste meio tornou-se com o seu crescimento um complicador notadamente para a recuperação.
Uma das causas deste complicador, segundo estudiosos e desenvolvedores tecnológicos, é que a informação inserida na Web está formatada para consulta de usuários humanos. A situação restringe o acesso à informação por “máquinas” ou “sistemas” programados.
A inserção de “máquinas” na busca e localização da informação na Web, e a concepção dos procedimentos aparecem em artigo de Tim Berners-Lee, “A Roadmap to the Semantic Web”, de 1998 (leitura básica aos estudantes e profissionais de biblioteconomia). No texto aparece pela primeira vez o termo “Web Semântica” (Semantic Web), e é destacada a necessidade de inserir a informação de forma a ser processada por máquinas. Indica, também, um conjunto de procedimentos para obter uma Web de organização automática da informação, realizada por máquinas (uma espécie de robô bibliotecário).
Em 2001, o autor em colaboração com dois outros (Hendler e Lassila), publica novo artigo sob o título “The Semantic Web”, onde apresenta as principais características desejadas para a futura Web. Salienta que as máquinas facilitarão novos produtos e serviços ao melhorar sua capacidade de processar e compreender a informação armazenada na Web. Como solução às limitações semânticas existentes é proposto tornar automaticamente processável a informação, e neste sentido a Web Semântica é definida como:
The Semantic Web is an extension of the current web in which information in given well-defined meaning, better enabling computers and people to work in cooperation...[ A Web Semântica é uma extensão da Web atual, onde a informação possui um significado bem definido, permitindo que computadores e pessoas trabalhem em cooperação].
Assim, a Web Semântica não seria uma nova Web, mas uma extensão da existente, com acréscimo de metadados para descrever os recursos de forma a serem localizados e selecionados por máquinas (também denominados agentes inteligentes). Os recursos eletrônicos, dispostos na rede, seriam melhores identificados.
Com base nestes princípios a Web Semântica converte-se em um campo significativo de pesquisa, congressos e grupos de estudos de várias áreas do conhecimento, incluindo a Biblioteconomia e a Ciência da Informação.
O conhecimento sobre a semântica da informação passa a ser chave para encontrar maneiras de expandir o espaço da Web, onde a maioria dos recursos só pode ser localizada por buscas sintáticas (busca de palavras codificadas e não de seu significado no contexto do conteúdo).
No desenvolvimento da Web Semântica baseada em metadados processáveis por máquina, um conjunto de camadas definem níveis distintos de representação da informação. A arquitetura contempla uma representação que varia desde um nível inferior (puramente sintético), até um nível superior, onde é possível determinar a validade da informação.
A arquitetura que sintetiza a concepção da Web Semântica foi proposta por Tim Berners-Lee. É expressa na Figura 1 e lembra uma pirâmide. A figura é familiar aos bibliotecários, e a sua compreensão permite visualizar o papel deste profissional na construção semântica da Web. Certamente, este texto não tem a pretensão de fornecer uma compreensão aprofundada da Web Semântica, mas estimular que estudantes e profissionais da área busquem o aprofundamento necessário sobre o tema. O texto é uma breve descrição panorâmica sobre a “pirâmide” estrutural da Web Semântica para não egípcios (iniciados), ainda que a terminologia técnica possa parecer Grego.
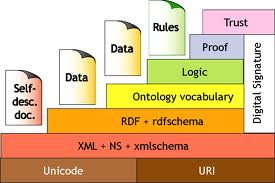
Figura – 01: Estrutura e Padrões da Web Semântica.
Olhando a Figura, ela se desmembra em:
1 – Camada sintática. É o nível inferior ou base da pirâmide. Seu objetivo é facilitar o intercâmbio de dados por meio de uma sintaxe de serialização concreta. Nesta camada situa-se o Unicode e os URIs. Unicode é um padrão que permite aos computadores representar e manipular, de forma consistente, texto de qualquer sistema de escrita existente. Adota codificação de caracteres internacionais onde cada caracter recebe um identificador único. Assim, um documento em XML (camada superior) pode ser representado independente ao idioma, plataforma ou programa que o gerencie. Já, os URIs – Identificadores Uniformes de Recursos (Universal Resource Identifier), permitem a identificação unívoca de recursos dentro da Web Semântica. A função principal do URI é identificar de forma não ambígua um recurso na Web.
2- Camada XML e XML Schema. O XML (eXtensible Markup Language) é uma linguagem de marcação para intercâmbio de dados utilizada pelas camadas superiores, entretanto não é de uso obrigatório já que outras linguagens poderiam ser utilizadas. O XML e o XML Schema oferecem a sintaxe necessária para o intercâmbio e persistência da informação.
3 – Camada RDF e RDF Schema. Proporciona flexibilidade para representar conceitos e regras lógicas relacionadas, o que gera valor agregado. O marco da descrição de recursos (Resource Description Framework – RDF) é a recomendação do W3C que define uma linguagem simples para expressar a tríplice relação entre Recurso – Propriedade – Valor (World Wide Web Consortium, 1999). RDF é uma linguagem declarativa que fornece um procedimento padronizado de utilização do XML para representar metadados no formato de sentenças sobre propriedades e relacionamentos entre itens na Web. Esses itens, denominados recursos, podem ser virtualmente qualquer objeto (texto, figura, vídeo e outros), desde que possuam um endereço Web. A especificação de RDF Schema, também recomendada pelo W3C, visa facilitar a interpretação semântica do RDF. Possibilita representar modelos semânticos, orientados a objeto, na forma de redes de conceitos. Entre os principais conceitos incluídos estão aqueles que permitem a definição de: classes, propriedades, subpropriedades, restrições de domínio e categoria, etiquetas e comentários. Utiliza-se o RDF Schema em conjunto com o RDF. Considera-se o RDF Schema um tipo de dicionário que pode ser lido por máquinas. O conjunto das duas representações é usualmente referenciado pela sigla RDFs.
4 – Camada Ontologia (Ontology). Contempla especificações formais e explícitas de conceitos expressos da camada inferior. Ontologias são modelos conceituais que devem capturar e explicitar o vocabulário necessário nas aplicações semânticas. Visam, assim, garantir uma comunicação livre de ambiguidade. Neste sentido, se considera as ontologias a língua franca da Web Semântica (BREITMAN, 2005). Existem distintas linguagens que permitem modelar a semântica necessária das ontologias. Exemplo de linguagens de modelagens: OIL, DAMIL+OIL e OWL (LAMARCA, 2002; BECHOFER, 2004).
5 – Camada Lógica (Logic). Permite definir as regras lógicas que infiram novos conhecimentos mediante um processo racional. Para poder comprovar que os resultados são corretos é preciso traduzir a racionalidade interna a uma linguagem de representação de provas (proof).
6 – Camada de Prova (Proof) e 7 – Camada de Confiança (Trust). Situados na parte alta da pirâmide encontra-se as camadas que devem fornecer mecanismos de comprovação de que a informação recebida é coerente desde o ponto de vista lógico. Estrutura-se no conjunto de regras das camadas inferiores. Deve ser capaz de mostrar de forma inteligível para humanos sua validade. Junto com a finalidade de validar a informação a partir do ponto de vista lógico, existe a necessidade de validá-la sob o ponto de vista da confiabilidade. Desta maneira, a confiabilidade da informação deve ser comprovável sob uma validade lógica com base em requisitos que: prove ser de fonte correta; não sofreu alteração; não possa ser negada por seu emissor.
8 – A assinatura digital (Digital Signature). Inserido na estrutura da pirâmide, sua função é incorporar mecanismos de segurança que garantam a confiabilidade da informação. Neste sentido, o objetivo é obter uma web de confiança (Web of Trust), onde a informação trocada seja confiável por meio de sua certificação.
9 – Padrões (pontilhado em vermelho). Destaca-se que o W3C é o órgão responsável por coordenar os processos de padronização das linguagens para Web Semântica. Por meio dos grupos de trabalhos especializados em distintas áreas de pesquisa, se desenvolve recomendações em conjunto com instituições acadêmicas, empresas e usuários (SURE, 2005).
A pirâmide proposta por Tim Bernes-Lee, inclui a evolução dos distintos padrões. Há recomendações para camadas sintáticas semelhantes, inclusive, a ontologia. Atualmente, se trabalha nas camadas mais altas da pirâmide: lógica, prova e confiança para se alcançar a proposta de um ambiente interativo para humanos e máquinas e de conteúdo recuperável por processo de inferência inteligente.
Importante ressaltar, que a pirâmide comentada é uma concepção inicial. Ao longo dos anos e a evolução dos estudos, a arquitetura tem passado por várias alterações e concepções no seu desenho original. Exemplo destas alterações é apresentado por Ramalho, Vidotti e Fujita (2007). Os autores enfocam os conceitos e as tecnologias subjacentes ao projeto da Web Semântica. Avaliam em que medida a área de Ciência da Informação pode contribuir para sua concretização e ressaltando os reflexos das novas abordagens tecnológicas de representação e recuperação de recursos informacionais no corpus teórico da área. Os autores também comentam a arquitetura redesenhada pelo próprio Bernes-Lee, em 2005. A arquitetura pode ser visualizada na Figura 2.
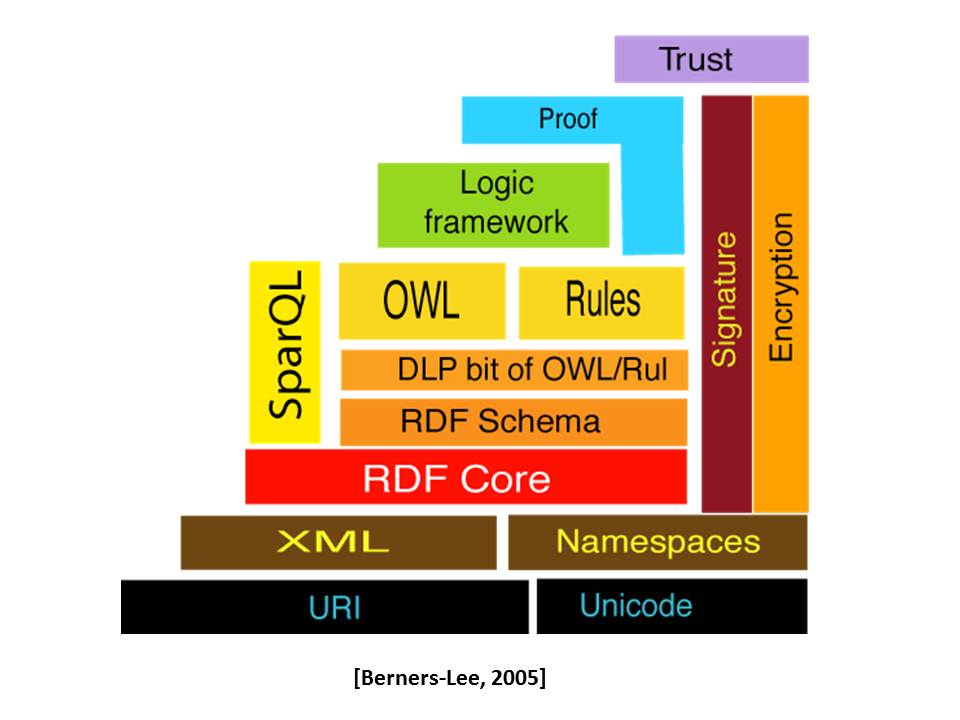
Figura 2: Arquitetura da web semântica proposta em 2005
Dos elementos inseridos no desenho da Figura 2 em relação Figura 1, destaque para:
§ Namespace: Coleção de nomes, identificados por um URI, que são utilizados em documentos XML para validar elementos e atributos.
§ RDF Core: Compreende as especificações do modelo e a sintaxe da Resource Description Framework (Estrutura de Descrição de Recursos). Descrição dos recursos por meio de suas propriedades e valores. A RDF é uma tecnologia para a modelagem semântica, sobre a qual podem ser criadas linguagens computacionais específicas.
§ SparQL: Linguagem computacional utilizada para realizar consultas a partir de estruturas RDF. Favorece a recuperação de informações. Tecnologia recém recomendada pelo W3C (http://www.w3.org/TR/rdf-sparql-query/).
§ DLP (Description Logic Programs): Constitui em subconjunto de sistemas computacionais baseados em representação do conhecimento: Lógica Descritiva (OWL DL) e Programação Lógica (F-Logic), fornecendo uma estrutura flexível.
§ OWL (Web Ontology Language): Linguagem computacional recomendada pelo W3C para o desenvolvimento de ontologias. Útil para descrever os aspectos semânticos dos termos utilizados e seus respectivos relacionamentos. Possibilita representações abrangentes das linguagens RDF e RDF Schema e favorece maior interoperabilidade.
§ Rules: Permite a definição de regras lógicas relacionadas aos recursos informacionais. A camada possibilita uma espécie de “Introdução Lógica”, enquanto que a camada superior, Logic Framework, possibilita a incorporação de “Lógicas Avançadas”.
§ Encryption: Processo em que as informações são criptografadas de modo que não possam ser interpretadas por qualquer pessoa ou sistema computacional, garantindo assim a confidencialidade das informações.
Concluindo
Segundo Ramalho, Vidotti e Fujita (2007), no âmbito do projeto Web Semântica há a necessidade de maior familiarização dos profissionais da informação com as tecnologias, para que as mesmas possam ser desenvolvidas e aplicadas a partir de princípios éticos sociais e não baseadas exclusivamente em conhecimentos e processos puramente técnicos. Afinal, os instrumentos de representação de informações desenvolvidos no âmbito da área de Ciência da Informação têm como objetivo básico propiciar meios adequados de representar e organizar conteúdos informacionais, possibilitando responder de maneira eficiente às buscas realizadas diretamente pelos usuários finais.
Indicação de leitura:
Bechofer, S. e outros. OWL Web Ontology Language. W3C, 2004.
Bernes-Lee, T. Semantic Web Concepts. 2005.
Bernes-Lee, T. A Roadmap to the Semantic Web .W3C, 1998.
Bernes-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Scientific American, vol. 5, n.284, p. 34-43, 2001.
BREITMAN, K.K. Web Semântica: a internet do future. Rio de Janeiro : LTC, 2005.
Lamarca Lapuente, M.J. DAML – OIL. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. 2009.
Ramalho, R.A.; Vidotti, S.A.B.G; Fujita, M.S.L. Web semântica: uma investigação sob o olhar da Ciência da Informação. DataGramaZero - Revista de Ciência da Informação - vol.8, n.6, dez/07.
Sure, Y; Studer, R. Semantic Web Technologies for Digital Libraries. Library Management, vol.26, n. 4/5, p. 190-195, 2005.
World Wide Web Consortium. Resource Description Framework (RDF): Model and Syntax Specification. W3C, 1999.